Qwen大模型实践之初体验
测试机器, 使用InternStudio提供的开发机,配置如下:
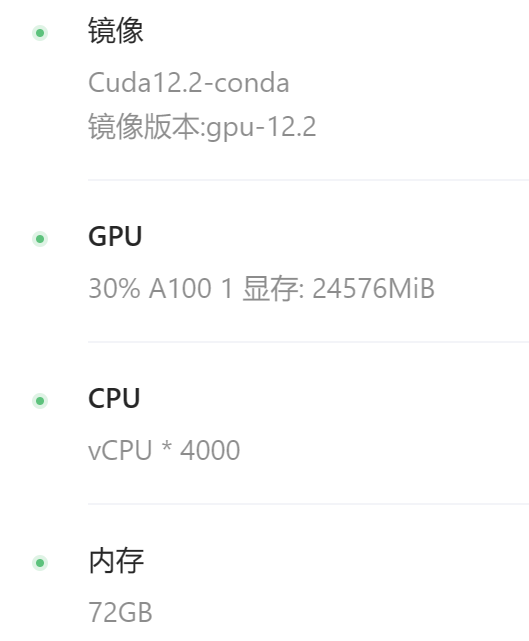
部分资源详细信息:
# CPU
Intel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz
# GPU
(base) root@intern-studio-50014188:~# studio-smi
Running studio-smi by vgpu-smi
Wed May 08 10:13:32 2024
+------------------------------------------------------------------------------+
| VGPU-SMI 1.7.13 Driver Version: 535.54.03 CUDA Version: 12.2 |
+-------------------------------------------+----------------------------------+
| GPU Name Bus-Id | Memory-Usage GPU-Util |
|===========================================+==================================|
| 0 NVIDIA A100-SXM... 00000000:48:00.0 | 0MiB / 24566MiB 0% / 30% |
+-------------------------------------------+----------------------------------+
# 操作系统
(base) root@intern-studio-50014188:~# cat /etc/issue
Ubuntu 20.04.6 LTS \n \l
# python
(base) root@intern-studio-50014188:~# python3 --version
Python 3.11.5
1. 环境准备
1.1 环境要求
-
python 3.8及以上版本 -
pytorch 1.12及以上版本,推荐2.0及以上版本 -
transformers 4.32及以上版本 -
建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
1.2 基本环境准备
1.2.1 下载Qwen代码库并安装基础环境
# 下载Qwen代码库,并创建python虚拟环境
(base) root@intern-studio-50014188:~# git clone https://github.com/QwenLM/Qwen.git
(base) root@intern-studio-50014188:~# conda create -n qwen python=3.10
(base) root@intern-studio-50014188:~# conda activate qwen
(qwen) root@intern-studio-50014188:~# cd Qwen/
(qwen) root@intern-studio-50014188:~/Qwen# ls
FAQ.md LICENSE README.md README_FR.md 'Tongyi Qianwen RESEARCH LICENSE AGREEMENT' cli_demo.py eval finetune.py requirements.txt tech_memo.md tokenization_note_zh.md
FAQ_ja.md NOTICE README_CN.md README_JA.md ascend-support dcu-support examples openai_api.py requirements_web_demo.txt tokenization_note.md utils.py
FAQ_zh.md QWEN_TECHNICAL_REPORT.pdf README_ES.md 'Tongyi Qianwen LICENSE AGREEMENT' assets docker finetune recipes run_gptq.py tokenization_note_ja.md web_demo.py
(qwen) root@intern-studio-50014188:~/Qwen# pip install -r requirements.txt
# 遇到错误:
ERROR: tiktoken 0.6.0 has requirement requests>=2.26.0, but you'll have requests 2.22.0 which is incompatible.
# 解决:
pip install requests==2.31.0
1.2.2 安装flash-attenion加速
如果你的显卡支持fp16或bf16精度,我们还推荐安装flash-attention(当前已支持flash attention 2)来提高你的运行效率以及降低显存占用。(flash-attention只是可选项,不安装也可正常运行该项目):
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
pip install ninja
pip install .
# 下方安装可选,安装可能比较缓慢。
# pip install csrc/layer_norm
# 如果flash-attn版本高于2.1.1,下方无需安装。
# pip install csrc/rotary
之前使用自己的电脑(win11)直接基于源码安装flash-attenion,会遇到各种问题,上述环境下安装时间较长但是可以安装成功。
1.3 模型下载
模型下载有两种方式,一种是直接运行大模型demo程序,模型会自动下载,该种方式默认会从huggingface进行下载,国内网络无法直接下载或者速度较慢;另外一种就是通过modelscope(由阿里进行维护)进行下载,速度较快。建议通过modelscope下载。
1.3.1 demo程序自动下载
直接运行demo脚本,默认会从huggingface下载模型文件,下载后的路径(以Qwen-7B-Chat为例):
/root/.cache/huggingface/hub/models--Qwen--Qwen-7B-Chat/snapshots/93a65d34827a3cc269b727e67004743b723e2f83/
即使使用InternStudio的环境,下载速度在3-4M左右,对于至少数GB的模型来说速度较慢。
1.3.2 从国内社区进行下载
下面使用python脚本从modelscope下载模型,也可以直接到魔搭官网进行下载后导入到测试机。以下载Qwen-14B-Chat为例:
# 安装modelscope
(qwen) root@intern-studio-50014188:~# pip install modelscope
# 创建如下内容的python脚本
(qwen) root@intern-studio-50014188:~# cat Qwen_snapshot_download.py
from modelscope import snapshot_download
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-7B')
# model_dir = snapshot_download('qwen/Qwen-7B-Chat')
# model_dir = snapshot_download('qwen/Qwen-14B')
model_dir = snapshot_download('qwen/Qwen-14B-Chat')
# 运行脚本下载
(qwen) root@intern-studio-50014188:~# python3 Qwen_snapshot_download.py
# 下载后的模型路径:
(qwen) root@intern-studio-50014188:~/.cache/modelscope/hub/qwen/Qwen-14B-Chat# ls -alh
total 27G
drwxr-xr-x 2 root root 4.0K May 7 22:14 .
drwxr-xr-x 3 root root 4.0K May 7 22:04 ..
-rw-r--r-- 1 root root 41 May 7 22:04 .mdl
-rw------- 1 root root 2.5K May 7 22:14 .msc
-rw-r--r-- 1 root root 36 May 7 22:14 .mv
-rw------- 1 root root 6.8K May 7 22:04 LICENSE.md
-rw------- 1 root root 2.7K May 7 22:14 NOTICE.md
-rw------- 1 root root 33K May 7 22:14 README.md
-rw------- 1 root root 8.3K May 7 22:04 cache_autogptq_cuda_256.cpp
-rw------- 1 root root 51K May 7 22:04 cache_autogptq_cuda_kernel_256.cu
-rw------- 1 root root 910 May 7 22:04 config.json
-rw------- 1 root root 77 May 7 22:04 configuration.json
-rw------- 1 root root 2.3K May 7 22:04 configuration_qwen.py
-rw------- 1 root root 1.9K May 7 22:04 cpp_kernels.py
-rw------- 1 root root 249 May 7 22:04 generation_config.json
-rw------- 1 root root 2.0G May 7 22:05 model-00001-of-00015.safetensors
-rw------- 1 root root 1.9G May 7 22:06 model-00002-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:06 model-00003-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:07 model-00004-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:08 model-00005-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:08 model-00006-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:09 model-00007-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:09 model-00008-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:10 model-00009-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:10 model-00010-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:11 model-00011-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:12 model-00012-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:12 model-00013-of-00015.safetensors
-rw------- 1 root root 1.8G May 7 22:13 model-00014-of-00015.safetensors
-rw------- 1 root root 1.5G May 7 22:14 model-00015-of-00015.safetensors
-rw------- 1 root root 24K May 7 22:14 model.safetensors.index.json
-rw------- 1 root root 55K May 7 22:14 modeling_qwen.py
-rw------- 1 root root 2.5M May 7 22:14 qwen.tiktoken
-rw------- 1 root root 15K May 7 22:14 qwen_generation_utils.py
-rw------- 1 root root 9.4K May 7 22:14 tokenization_qwen.py
-rw------- 1 root root 173 May 7 22:14 tokenizer_config.json
# 将下载的模型移Qwen仓库路径下
(qwen) root@intern-studio-50014188:~/Qwen# pwd
/root/Qwen
(qwen) root@intern-studio-50014188:~/Qwen# mv ~/.cache/modelscope/hub/qwen/Qwen-14B-Chat .
2. 运行demo程序
demo程序有多个可以进行测试,一种是官方readme文件中给出的实例程序,直接运行,prompt直接写在程序中,打印大模型的回复内容,这种方式没有交互方式;另外一种是仓库中带有的cli_demo和web_demo,分别基于命令行和web界面进行交换体验。
2.1 快速体验demo程序
使用Transformers或者ModelScope来使用我们的模型,测试官方提供的测试脚本。
2.1.1 huggingface transformers测试程序
使用Qwen-14B-Chat进行推理。在仓库路径下创建如下python文件,注意from_pretrained中的模型文件路径和名称(3个地方需要进行修改)。
(qwen) root@intern-studio-50014188:~/Qwen# cat hg_transformer_Qwen14BChat_demo1.py
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 可选的模型包括: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("./Qwen-14B-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained("./Qwen-14B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("./Qwen-14B-Chat", trust_remote_code=True)
# 第一轮对话
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二轮对话
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
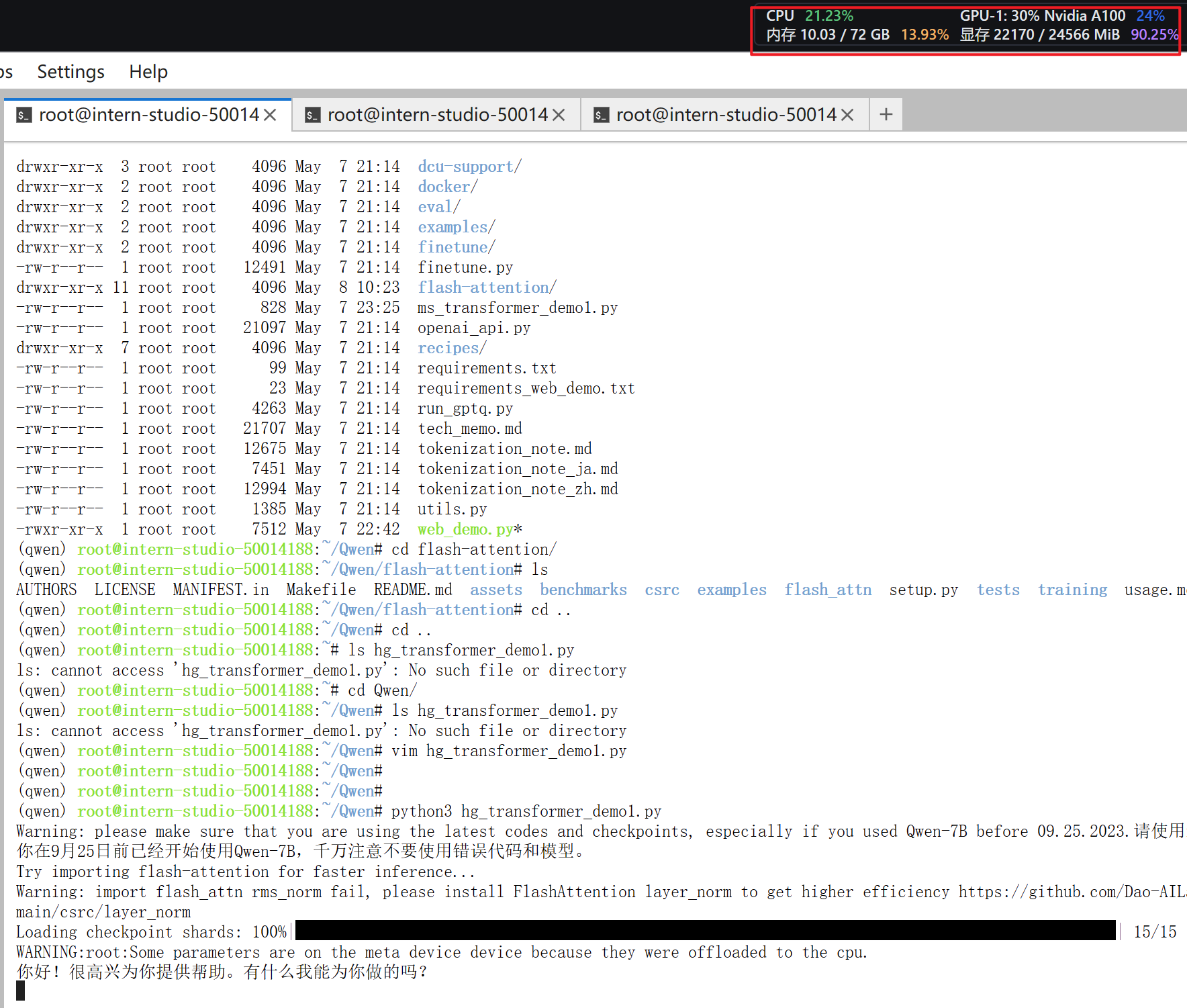
通过python3 hg_transformer_Qwen14BChat_demo1.py执行,实际体验推理过程较慢,24GB的A100显存资源基本满载。由于没有交互,故事部分等待了很长时间才打印输出内容。测试安装FlashAttension之后提速效果不明显。
(qwen) root@intern-studio-50014188:~/Qwen# python3 hg_transformer_Qwen14BChat_demo1.py
Warning: please make sure that you are using the latest codes and checkpoints, especially if you used Qwen-7B before 09.25.2023.请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。
Try importing flash-attention for faster inference...
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|██████████████████████████████████████████████████| 15/15 [00:30<00:00, 2.03s/it]
WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
你好!有什么我可以帮助你的吗?
当然,这是一个叫杰克的年轻人的故事。
杰克出生在一个普通的家庭,他的父母都是工人。他从小就对科技和创新有着浓厚的兴趣,并且一直梦想着能够创造出自己的产品来改变世界。
在大学期间,杰克就开始了自己的创业之路。他创立了一家初创公司,专注于开发新型的智能家居设备。但是,初期的发展并不顺利,他们的产品在市场上并没有得到很好的反响。
尽管面临困难,但杰克没有放弃。他深入研究市场需求,并调整了公司的战略方向。他决定将目光投向人工智能领域,打造一款具有自我学习能力的家庭机器人。
经过无数次的努力和失败,杰克和他的团队终于研发出了这款智能机器人。这款机器人的出现引起了市场的广泛关注,销售情况也十分理想。
几年后,杰克的公司已经发展成为一家全球知名的高科技企业,他的产品被广泛应用在世界各地的家庭中,改善了人们的生活方式。他也因此获得了多项科技创新大奖,成为了年轻一代的创业偶像。
这个故事告诉我们,只要有决心、勇气和创新精神,无论起点多么平凡,我们都可以通过自己的努力和智慧实现伟大的梦想。
《从零开始:一位青年的科技创业之旅》
资源占用:
2.1.2 ModelScope测试程序
使用Qwen-7B-chat进行推理。在仓库路径下创建如下python文件,注意from_pretrained中的模型文件路径和名称(3个地方需要进行修改)。
(base) root@intern-studio-50014188:~/Qwen# cat ms_transformer_Qwen7BChat_demo2.py
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
# 可选的模型包括: "qwen/Qwen-7B-Chat", "qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("./Qwen-7B-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
model.generation_config = GenerationConfig.from_pretrained("./Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
print(response)
response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history)
print(response)
运行demo程序,GPU最高占用约15G,推理过程较上面的快:
(qwen) root@intern-studio-50014188:~/Qwen# python3 ms_transformer_Qwen7BChat_demo2.py
2024-05-08 11:30:44,479 - modelscope - INFO - PyTorch version 2.3.0 Found.
2024-05-08 11:30:44,479 - modelscope - INFO - Loading ast index from /root/.cache/modelscope/ast_indexer
2024-05-08 11:30:44,558 - modelscope - INFO - Updating the files for the changes of local files, first time updating will take longer time! Please wait till updating done!
2024-05-08 11:30:44,567 - modelscope - INFO - AST-Scanning the path "/usr/local/lib/python3.8/dist-packages/modelscope" with the following sub folders ['models', 'metrics', 'pipelines', 'preprocessors', 'trainers', 'msdatasets', 'exporters']
2024-05-08 11:30:57,465 - modelscope - INFO - Scanning done! A number of 976 components indexed or updated! Time consumed 12.89767575263977s
2024-05-08 11:30:57,496 - modelscope - INFO - Loading done! Current index file version is 1.14.0, with md5 e9dc05602b3b26234574a15f8c3fe080 and a total number of 976 components indexed
Try importing flash-attention for faster inference...
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████| 8/8 [00:43<00:00, 5.46s/it]
你好!很高兴为你提供帮助。有什么我可以帮你的吗?
浙江省会是杭州市。
杭州市有很多著名的旅游景点,例如西湖、灵隐寺、西溪湿地公园等。西湖是杭州最著名的景点之一,拥有美丽的湖泊、绿树环绕和历史文化遗迹;灵隐寺位于杭州市西湖区灵隐山下,是中国佛教禅宗四大名刹之一;西溪湿地公园是一个自然保护区,拥有丰富的野生动植物资源和独特的湿地景观。
资源占用情况如下:
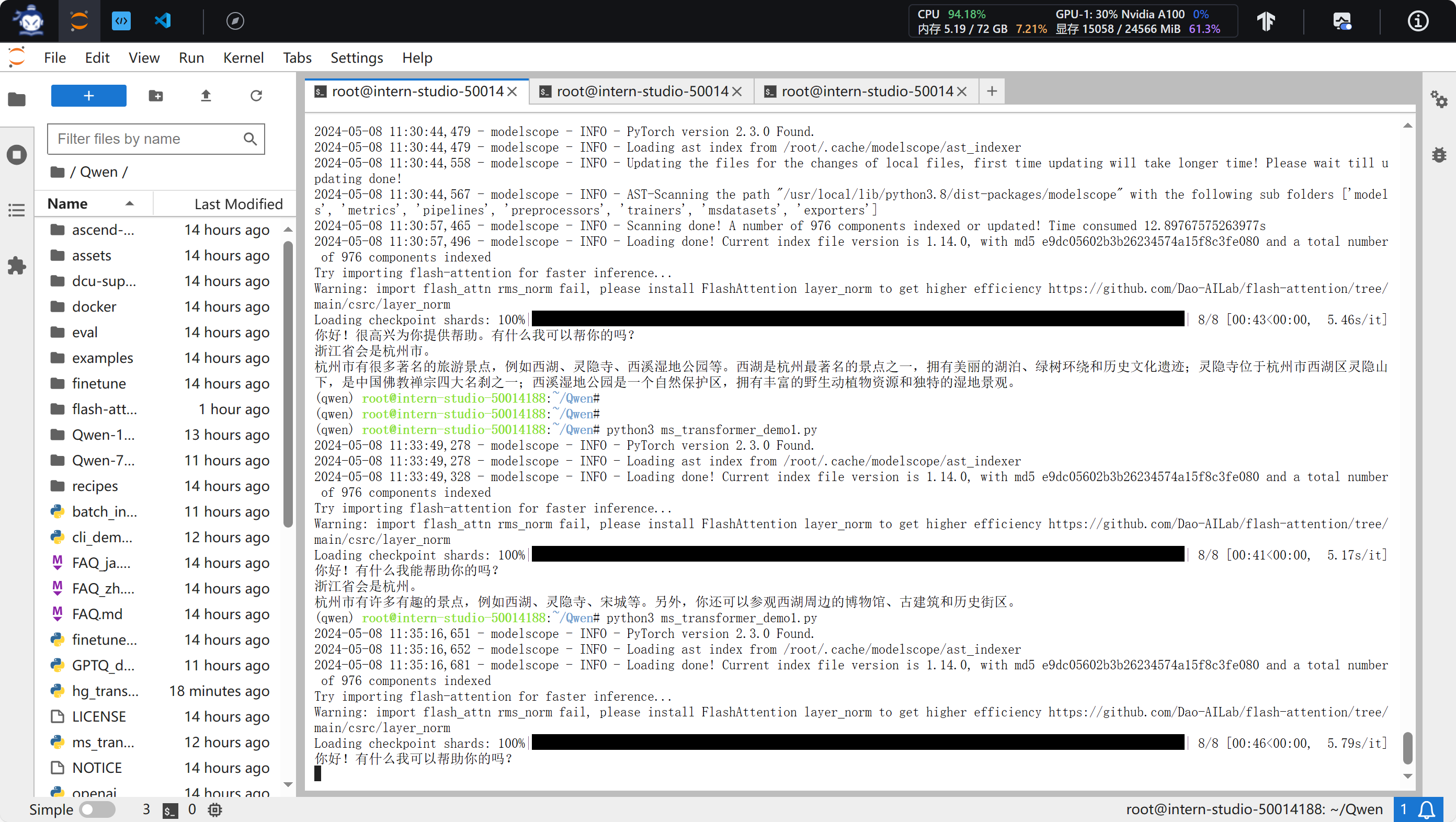
进行交叉测试,使用huggingface和modelscope的transformers分别测试demo1(讲故事),推理速度都较慢。
安装layer_norm后再次使用demo1程序进行测试,推理速度和资源占用优化提升不大。
(qwen) root@intern-studio-50014188:~/Qwen# cd flash-attention/
(qwen) root@intern-studio-50014188:~/Qwen/flash-attention# ls
AUTHORS LICENSE MANIFEST.in Makefile README.md assets benchmarks csrc examples flash_attn setup.py tests training usage.md
(qwen) root@intern-studio-50014188:~/Qwen/flash-attention# pip install csrc/layer_norm
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing ./csrc/layer_norm
Building wheels for collected packages: dropout-layer-norm
Building wheel for dropout-layer-norm (setup.py) ... done
Created wheel for dropout-layer-norm: filename=dropout_layer_norm-0.1-cp38-cp38-linux_x86_64.whl size=152352178 sha256=a9fcf2fe350ccaad2cd2c943dc5aa634d9b398fba473e09d01518dca1e0cb828
Stored in directory: /tmp/pip-ephem-wheel-cache-trak08bs/wheels/7a/c3/d2/992b2e303949af1a2128a2308268a95ec308309657cd12e497
Successfully built dropout-layer-norm
Installing collected packages: dropout-layer-norm
Successfully installed dropout-layer-norm-0.1
2.2 交互体验demo
上述的demo程序没有交互流程,下面通过命令行和web界面两种方式测试大模型。除了可以进行交互外,另外就是运行demo程序后,模型文件会一直加载到GPU中,不用每次推理都进行重复加载,直到停止程序为止。
2.2.1 命令行方式
# 命令行运行模型,修改cli_demo.py,修改模型路径:
(qwen) root@intern-studio-50014188:~/Qwen# vim cli_demo.py
...
DEFAULT_CKPT_PATH = './Qwen-14B-Chat'
...
# 运行demo程序:
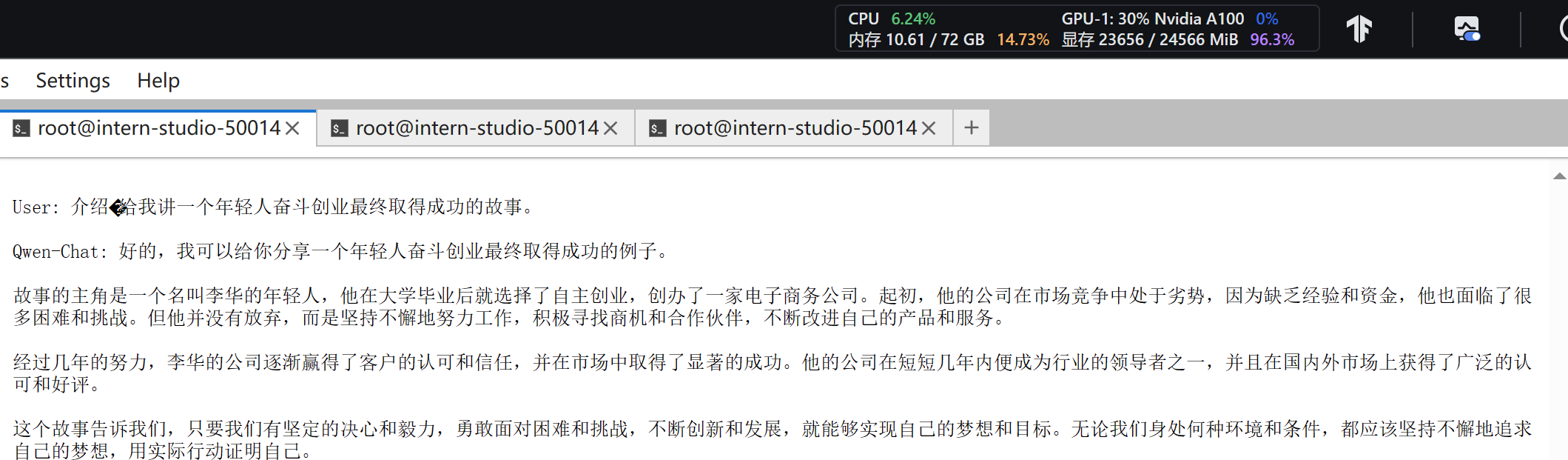
(qwen) root@intern-studio-50014188:~/Qwen# python3 cli_demo.py
...
效果如下,相对于上面的程序,推理过程是渐进式的,虽然速度仍然较慢:
2.2.2 web界面方式
# web界面运行模型,修改web_demo.py,修改模型路径:
DEFAULT_CKPT_PATH = './Qwen-14B-Chat'
# 安装依赖:
(qwen) root@intern-studio-50014188:~/Qwen# pip install gradio mdtex2html
运行web界面:
(qwen) root@intern-studio-50014188:~/Qwen# python3 web_demo.py
Warning: please make sure that you are using the latest codes and checkpoints, especially if you used Qwen-7B before 09.25.2023.请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。
The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
Try importing flash-attention for faster inference...
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
/usr/local/lib/python3.8/dist-packages/accelerate/utils/modeling.py:1365: UserWarning: Current model requires 2621568 bytes of buffer for offloaded layers, which seems does not fit any GPU's remaining memory. If you are experiencing a OOM later, please consider using offload_buffers=True.
warnings.warn(
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████| 15/15 [00:06<00:00, 2.25it/s]
Running on local URL: http://127.0.0.1:8000
由于webserver运行在远端开发机上,需要在本地电脑配置ssh端口转发,本地电脑如果是windows,需要是最新的win10或者win11.自带ssh命令。命令如下:
ssh -CNg -L 8000:127.0.0.1:8000 -o StrictHostKeyChecking=no -p 46672 root@ssh.intern-ai.org.cn
将远端机器的8000端口转发到本地的8000端口。ssh连接远端机器的端口(46672)和域名(ssh.intern-ai.org.cn)可以都提供测试机的平台查看。
然后终端打开http://127.0.0.1:8000 即可打开模型对话界面。
测试相同问答,效果如下:
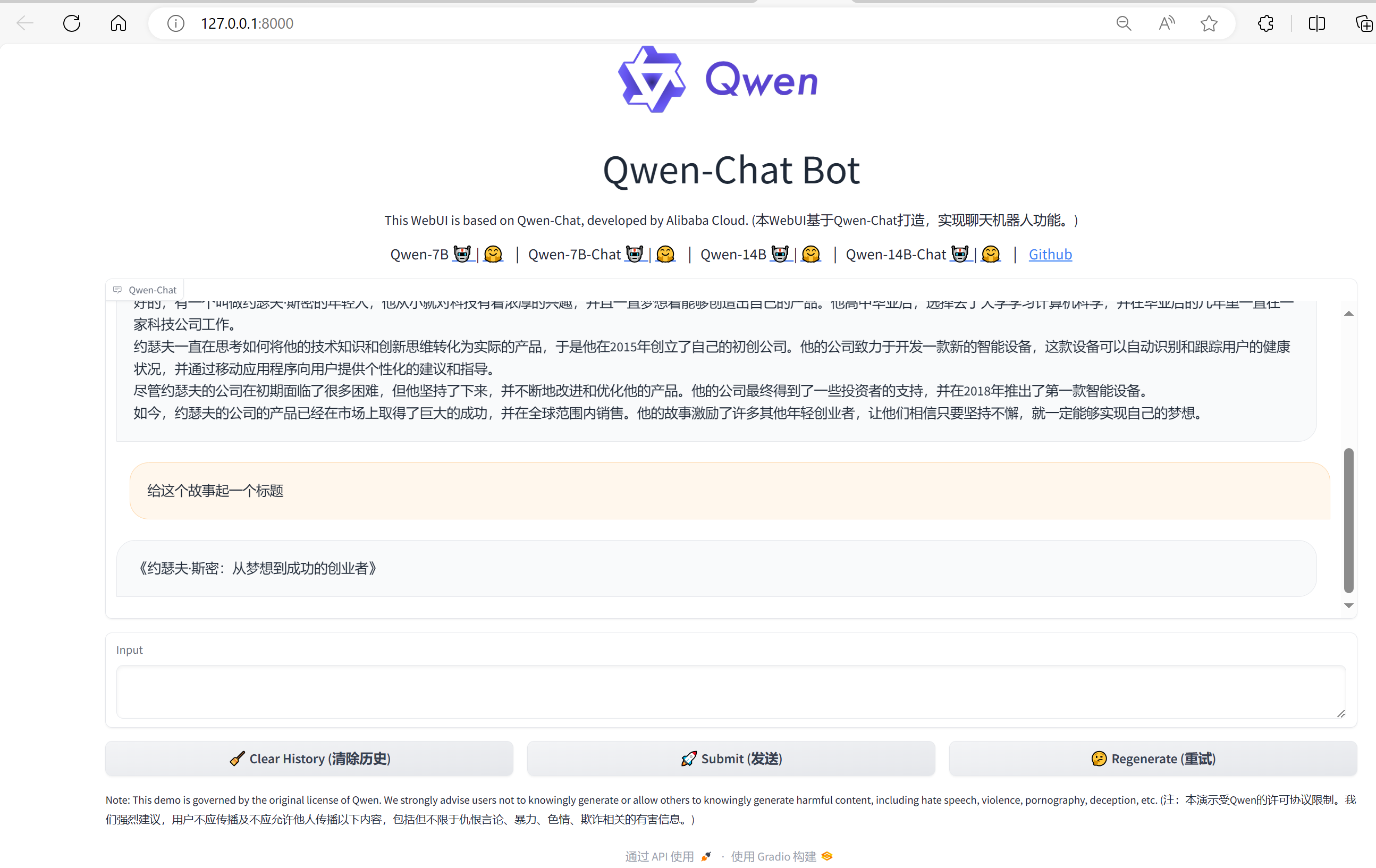
注意:
在运行demo程序之前,通过ps命令查看确保之前运行的demo程序已经关闭,否则会导致GPU资源不足。
本文由 mdnice 多平台发布